Keepalived per la gestione semplificata di Asterisk Cluster
Quando si immagina un Cluster, si è sempre portati a pensare ad un sistema complesso, ingombrante, costoso e difficile da gestire. Ma un sistema di High Avaialability basico non deve per forza esserlo, anzi utilizzando Keepalived ed il protocollo VRRP si possono ottenere ottimi risultati con il minimo sforzo.
Keepalived è un sistema di routing software che rende disponibili le strutture necessarie per ottenere un Sistema di Load Balancing e/o High Availability ed ha alla sua base il protocollo VRRP ( Virtual Router Redundancy Protocol ) , un protocollo nato per gestire la ridondanza negli apparati di networking, ma che fornisce gli stessi servizi in un sistema server.
Il concetto principale di un sistema di HA rimane sempre uno, il VIP (virtual Ip Addres), l’indirizzo raggiungibile pubblicamente ed il protocollo VRRP si occuperà di determinare l’host “intestatario” di suddetto Ip, almeno fino a quando esso soddisferà i requisiti di eligibilità. In caso contrario, in cui l’host si dovesse “perdere”, VRRP fornirà il meccanismo per rilevare il server fault e trasferire la “proprietà” del VIP ad un host rimasto a disposizione del cluster, parimente configurato per fornire i servizi del cluster.
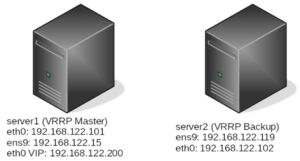
server1# ip -brief address show
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64server2# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.102/24 fe80::5054:ff:fe04:2c5d/64
Il VIP è sul server1, ma qualora interrompessimo il servizio keepalived su di essoserver1# systemctl stop keepalived
server1# ip -brief address show
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
Questo passerà automaticamente sul secondo nodoserver2# ip -brief address show
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.102/24 192.168.122.200/24 fe80::5054:ff:fe04:2c5d/64
Nel caso di un cluster Asterisk, DRBD si occuperà della parte file di configurazione /storage e la replicazione Attiva / Passiva per la parte DB (MySQL).
In un sistema come Asterisk, fornire un sistema di Clustering realmente efficente, cioè con nessuna perdita di comunicazione, risulta molto complicato da ottenere. Il protocollo Sip per come implementa il servizio Registrar e Location non consente la gestione del fail-over in maniera trasparente. Con qualche artificio si può girarci intorno, ma nei casi “normali” uno o due minuti di downtime sarà da tenere in conto, quanto meno per lasciare il tempo ai vari apparati di ri-registrarsi sulla nuova istanza del cluster.